8.9. Payload Keywords
Payload keywords inspect the content of the payload of a packet or stream.
8.9.1. content
The content keyword is very important in signatures. Between the quotation marks you can write on what you would like the signature to match. The most simple format of content is:
content: "............";
It is possible to use several contents in a signature.
Contents match on bytes. There are 256 different values of a byte
(0-255). You can match on all characters; from a till z, upper case
and lower case and also on all special signs. But not all of the bytes
are printable characters. For these bytes heximal notations are
used. Many programming languages use 0x00 as a notation, where 0x
means it concerns a binary value, however the rule language uses
|00| as a notation. This kind of notation can also be used for
printable characters.
Example:
|61| is a
|61 61| is aa
|41| is A
|21| is !
|0D| is carriage return
|0A| is line feed
There are characters you can not use in the content because they are already important in the signature. For matching on these characters you should use the heximal notation. These are:
" |22|
; |3B|
: |3A|
| |7C|
It is a convention to write the heximal notation in upper case characters.
To write for instance http:// in the content of a signature, you
should write it like this: content: "http|3A|//"; If you use a
heximal notation in a signature, make sure you always place it between
pipes. Otherwise the notation will be taken literally as part of the
content.
A few examples:
content:"a|0D|bc";
content:"|61 0D 62 63|";
content:"a|0D|b|63|";
It is possible to let a signature check the whole payload for a match with the content or to let it check specific parts of the payload. We come to that later. If you add nothing special to the signature, it will try to find a match in all the bytes of the payload.
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{3,}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
By default the pattern-matching is case sensitive. The content has to be accurate, otherwise there will not be a match.

Legend:
It is possible to use the ! for exceptions in contents as well.
For example:
alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"Outdated Firefox on Windows"; content:"User-Agent|3A| Mozilla/5.0 |28|Windows|3B| "; content:"Firefox/3."; distance:0; content:!"Firefox/3.6.13"; distance:-10; sid:9000000; rev:1;)
You see content:!"Firefox/3.6.13";. This means an alert will be
generated if the used version of Firefox is not 3.6.13.
Note
The following characters must be escaped inside the content:
; \ "
8.9.2. nocase
If you do not want to make a distinction between uppercase and lowercase characters, you can use nocase. The keyword nocase is a content modifier.
The format of this keyword is:
nocase;
You have to place it after the content you want to modify, like:
content: "abc"; nocase;
Example nocase:

It has no influence on other contents in the signature.
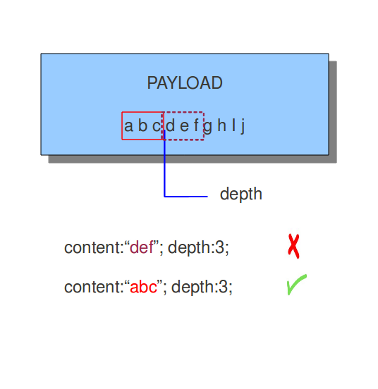
8.9.3. depth
The depth keyword is a absolute content modifier. It comes after the content. The depth content modifier comes with a mandatory numeric value, like:
depth:12;
The number after depth designates how many bytes from the beginning of the payload will be checked.
Example:
8.9.4. startswith
The startswith keyword is similar to depth. It takes no arguments
and must follow a content keyword. It modifies the content to match
exactly at the start of a buffer.
Example:
content:"GET|20|"; startswith;
startswith is a short hand notation for:
content:"GET|20|"; depth:4; offset:0;
startswith cannot be mixed with depth, offset, within or
distance for the same pattern.
8.9.5. endswith
The endswith keyword is similar to isdataat:!1,relative;. It takes no
arguments and must follow a content keyword. It modifies the content to
match exactly at the end of a buffer.
Example:
content:".php"; endswith;
endswith is a short hand notation for:
content:".php"; isdataat:!1,relative;
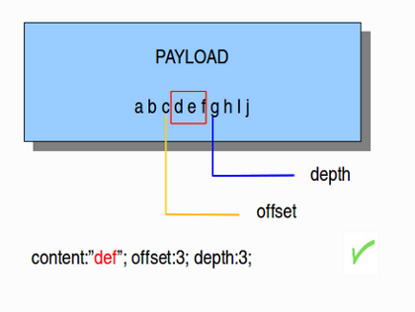
8.9.6. offset
The offset keyword designates from which byte in the payload will be checked to find a match. For instance offset:3; checks the fourth byte and further.

The keywords offset and depth can be combined and are often used together.
For example:
content:"def"; offset:3; depth:3;
If this was used in a signature, it would check the payload from the third byte till the sixth byte.
8.9.7. distance
The keyword distance is a relative content modifier. This means it indicates a relation between this content keyword and the content preceding it. Distance has its influence after the preceding match. The keyword distance comes with a mandatory numeric value. The value you give distance, determines the byte in the payload from which will be checked for a match relative to the previous match. Distance only determines where Suricata will start looking for a pattern. So, distance:5; means the pattern can be anywhere after the previous match + 5 bytes. For limiting how far after the last match Suricata needs to look, use 'within'.
The absolute value for distance must be less than or equal to 1MB (1048576).
Examples of distance:

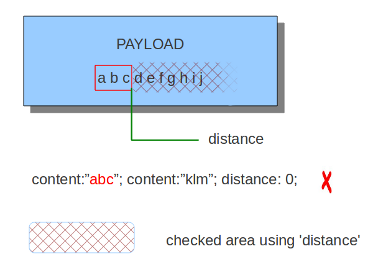

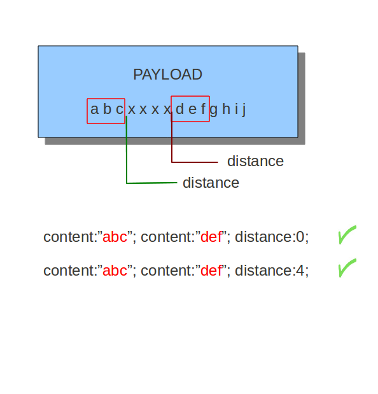
Distance can also be a negative number. It can be used to check for matches with partly the same content (see example) or for a content even completely before it. This is not very often used though. It is possible to attain the same results with other keywords.

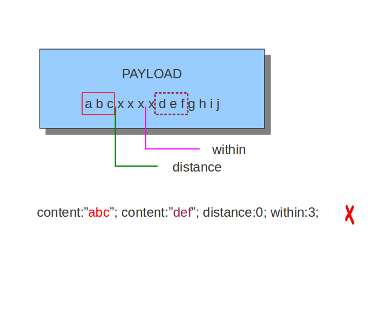
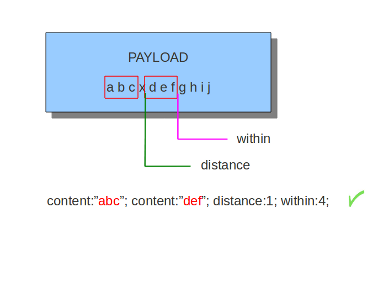
8.9.8. within
The keyword within is relative to the preceding match. The keyword within comes with a mandatory numeric value. Using within makes sure there will only be a match if the content matches with the payload within the set amount of bytes. Within can not be 0 (zero)
The absolute value for within must be less than or equal to 1MB (1048576).
Example:

Example of matching with within:

The second content has to fall/come 'within 3 ' from the first content.
As mentioned before, distance and within can be very well combined in a signature. If you want Suricata to check a specific part of the payload for a match, use within.
8.9.9. rawbytes
The rawbytes keyword has no effect but is included to be compatible with signatures that use it, for example signatures used with Snort.
8.9.10. isdataat
The purpose of the isdataat keyword is to look if there is still data at a specific part of the payload. The keyword starts with a number (the position) and then optional followed by 'relative' separated by a comma and the option rawbytes. You use the word 'relative' to know if there is still data at a specific part of the payload relative to the last match.
So you can use both examples:
isdataat:512;
isdataat:50, relative;
The first example illustrates a signature which searches for byte 512 of the payload. The second example illustrates a signature searching for byte 50 after the last match.
You can also use the negation (!) before isdataat.

8.9.10.1. absolute vs relative values
The absolute isdataat checks will succeed if the offset used is
less than the size of the inspection buffer.
For relative isdataat checks, there is a 1 byte difference vs
the absolute handling.
Matching will succeed if the relative offset is less than or equal to
the size of the inspection buffer. This is different from absolute
isdataat checks.
As an example, consider a 32 byte payload:
rule statement |
Match? |
|
Yes |
|
No |
|
Yes |
|
Yes |
|
No |
Another example, consider the following payload:
Index |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
Value |
a |
b |
c |
d |
e |
f |
g |
h |
Then the following rules match the payload as follows:
Rule statement |
Match? |
|
Yes |
|
No |
|
Yes |
|
Yes |
|
No |
|
Yes |
|
Yes |
|
No |
These differences are also discussed in Differences From Snort.
A discussion of this difference can be found at https://redmine.openinfosecfoundation.org/issues/8031
8.9.11. absent
The keyword absent checks that a sticky buffer does not exist.
It can be used without any argument to match only on absent buffer :
Example of absent in a rule:
alert http any any -> any any (msg:"HTTP request without referer"; http.referer; absent; sid:1; rev:1;)
It can take an argument "or_else" to match on absent buffer or on what comes next such as negated content, for instance :
alert http any any -> any any (msg:"HTTP request without referer"; http.referer; absent: or_else; content: !"abc"; sid:1; rev:1;)
For files (i.e file.data), absent means there are no files in the transaction.
8.9.12. bsize
With the bsize keyword, you can match on the length of the buffer. This adds
precision to the content match, previously this could have been done with isdataat.
bsize uses an unsigned 64-bit integer.
An optional operator can be specified; if no operator is present, the operator will default to '='. When a relational operator is used, e.g., '<', '>' or '<>' (range), the bsize value will be compared using the relational operator. Ranges are exclusive.
If one or more content keywords precedes bsize, each occurrence of content
will be inspected and an error will be raised if the content length and the bsize
value prevent a match.
Format:
bsize:<number>;
bsize:=<number>;
bsize:<<number>;
bsize:><number>;
bsize:<lo-number><><hi-number>;
Examples of bsize in a rule:
alert dns any any -> any any (msg:"bsize exact buffer size"; dns.query; content:"google.com"; bsize:10; sid:1; rev:1;)
alert dns any any -> any any (msg:"bsize less than value"; dns.query; content:"google.com"; bsize:<25; sid:2; rev:1;)
alert dns any any -> any any (msg:"bsize buffer less than or equal value"; dns.query; content:"google.com"; bsize:<=20; sid:3; rev:1;)
alert dns any any -> any any (msg:"bsize buffer greater than value"; dns.query; content:"google.com"; bsize:>8; sid:4; rev:1;)
alert dns any any -> any any (msg:"bsize buffer greater than or equal value"; dns.query; content:"google.com"; bsize:>=8; sid:5; rev:1;)
alert dns any any -> any any (msg:"bsize buffer range value"; dns.query; content:"google.com"; bsize:8<>20; sid:6; rev:1;)
alert dns any any -> any any (msg:"test bsize rule"; dns.query; content:"short"; bsize:<10; sid:124; rev:1;)
alert dns any any -> any any (msg:"test bsize rule"; dns.query; content:"longer string"; bsize:>10; sid:125; rev:1;)
alert dns any any -> any any (msg:"test bsize rule"; dns.query; content:"middle"; bsize:6<>15; sid:126; rev:1;)
To emphasize how range works: in the example above, a match will occur if
bsize is greater than 6 and less than 15.
8.9.13. dsize
With the dsize keyword, you can match on the size of the packet payload/data. You can use the keyword for example to look for abnormal sizes of payloads which are equal to some n i.e. 'dsize:n' not equal 'dsize:!n' less than 'dsize:<n' or greater than 'dsize:>n' This may be convenient in detecting buffer overflows.
dsize cannot be used when using app/streamlayer protocol keywords (i.e. http.uri)
dsize uses an unsigned 16-bit integer.
Format:
dsize:[<>!]number; || dsize:min<>max;
Examples of dsize values:
alert tcp any any -> any any (msg:"dsize exact size"; dsize:10; sid:1; rev:1;)
alert tcp any any -> any any (msg:"dsize less than value"; dsize:<10; sid:2; rev:1;)
alert tcp any any -> any any (msg:"dsize less than or equal value"; dsize:<=10; sid:3; rev:1;)
alert tcp any any -> any any (msg:"dsize greater than value"; dsize:>8; sid:4; rev:1;)
alert tcp any any -> any any (msg:"dsize greater than or equal value"; dsize:>=10; sid:5; rev:1;)
alert tcp any any -> any any (msg:"dsize range value"; dsize:8<>20; sid:6; rev:1;)
alert tcp any any -> any any (msg:"dsize not equal value"; dsize:!9; sid:7; rev:1;)
8.9.14. byte_test
The byte_test keyword extracts <num of bytes> and performs an operation selected
with <operator> against the value in <test value> at a particular <offset>.
The <bitmask value> is applied to the extracted bytes (before the operator is applied),
and the final result will be right shifted one bit for each trailing 0 in
the <bitmask value>.
Format:
byte_test:<num of bytes> | <variable_name>, [!]<operator>, <test value>, <offset> [,relative] \
[,<endian>][, string, <num type>][, dce][, bitmask <bitmask value>];
<num of bytes> |
The number of bytes selected from the packet to be converted or the name of a byte_extract/byte_math variable. |
<operator> |
|
<value> |
Value to test the converted value against [hex or decimal accepted] |
<offset> |
Number of bytes into the payload |
[relative] |
Offset relative to last content match |
[endian] |
Type of number being read: - big (Most significant byte at lowest address) - little (Most significant byte at the highest address) |
[string] <num> |
|
[dce] |
Allow the DCE module to determine the byte order |
[bitmask] |
Applies the AND operator on the bytes converted |
- alert tcp any any -> any any
(msg:"Byte_Test Example - Num = Value"; content:"|00 01 00 02|"; byte_test:2,=,0x01,0;)
- alert tcp any any -> any any
(msg:"Byte_Test Example - Num = Value relative to content"; content:"|00 01 00 02|"; byte_test:2,=,0x03,2,relative;)
- alert tcp any any -> any any
(msg:"Byte_Test Example - Num != Value"; content:"|00 01 00 02|"; byte_test:2,!=,0x06,0;)
- alert tcp any any -> any any
(msg:"Byte_Test Example - Detect Large Values"; content:"|00 01 00 02|"; byte_test:2,>,1000,1,relative; sid:1;)
- alert tcp any any -> any any
(msg:"Byte_Test Example - Lowest bit is set"; content:"|00 01 00 02|"; byte_test:2,&,0x01,12,relative;)
- alert tcp any any -> any any (msg:"Byte_Test Example - Compare to String";
content:"foobar"; byte_test:4,=,1337,1,relative,string,dec; sid:1;)
8.9.15. byte_math
The byte_math keyword adds the capability to perform mathematical operations on extracted values with
an existing variable or a specified value.
When relative is included, there must be a previous content or pcre match.
Note: if oper is / and the divisor is 0, there will never be a match on the byte_math keyword.
The result can be stored in a result variable and referenced by other rule options later in the rule.
Keyword |
Modifier |
|---|---|
content |
offset,depth,distance,within |
byte_test |
offset,value |
byte_jump |
offset |
isdataat |
offset |
Format:
byte_math:bytes <num of bytes> | <variable-name> , offset <offset>, oper <operator>, rvalue <rvalue>, \
result <result_var> [, relative] [, endian <endian>] [, string <number-type>] \
[, dce] [, bitmask <value>];
<num of bytes> |
The number of bytes selected from the packet or the name of a byte_extract variable. |
<offset> |
Number of bytes into the payload |
oper <operator> |
Mathematical operation to perform: +, -, *, /, <<, >> |
rvalue <rvalue> |
Value to perform the math operation with |
result <result-var> |
Where to store the computed value |
[relative] |
Offset relative to last content match |
[endian <type>] |
|
[string <num_type>] |
|
[dce] |
Allow the DCE module to determine the byte order |
[bitmask] <value> |
The AND operator will be applied to the extracted value The result will be right shifted by the number of bits equal to the number of trailing zeros in the mask |
- alert tcp any any -> any any
(msg:"Testing bytemath_body"; content:"|00 04 93 F3|"; content:"|00 00 00 07|"; distance:4; within:4; byte_math:bytes 4, offset 0, oper +, rvalue 248, result var, relative; sid: 1;)
- alert udp any any -> any any
(byte_extract: 1, 0, extracted_val, relative; byte_math: bytes 1, offset 1, oper +, rvalue extracted_val, result var; byte_test: 2, =, var, 13; msg:"Byte extract and byte math with byte test verification"; sid: 1;)
8.9.16. byte_jump
The byte_jump keyword allows for the ability to select a <num of bytes> from an <offset> and moves the detection pointer to that position. Content matches will then be based off the new position.
The bitmask value is applied to the extracted value before the multiplier. Additionally, the result of the bitmask operation is
right-shifted by the number of trailing zeroes in the bitmask value.
Format:
byte_jump:<num of bytes> | <variable-name>, <offset> [, relative][, multiplier <mult_value>] \
[, <endian>][, string, <num_type>][, align][, from_beginning][, from_end] \
[, post_offset <value>][, dce][, bitmask <value>];
<num of bytes> |
The number of bytes selected from the packet to be converted or the name of a byte_extract/byte_math variable. |
<offset> |
Number of bytes into the payload |
[relative] |
Offset relative to last content match |
[multiplier] <value> |
Multiple the converted byte by the <value> |
[endian] |
|
[string] <num_type> |
|
[align] |
Rounds the number up to the next 32bit boundary |
[from_beginning] |
Jumps forward from the beginning of the packet, instead of where the detection pointer is set |
[from_end] |
Jump will begin at the end of the payload, instead of where the detection point is set |
[post_offset] <value> |
After the jump operation has been performed, it will jump an additional number of bytes specified by <value> |
[dce] |
Allow the DCE module to determine the byte order |
[bitmask] <value> |
The AND operator will be applied by <value> and the converted bytes, then jump operation is performed |
- alert tcp any any -> any any
(msg:"Byte_Jump Example"; content:"Alice"; byte_jump:2,0; content:"Bob";)
- alert tcp any any -> any any
(msg:"Byte_Jump Multiple Jumps"; byte_jump:2,0; byte_jump:2,0,relative; content:"foobar"; distance:0; within:6;)
- alert tcp any any -> any any
(msg:"Byte_Jump From the End -8 Bytes"; byte_jump:0,0, from_end, post_offset -8; content:"|6c 33 33 74|"; distance:0 within:4;)
8.9.17. byte_extract
The byte_extract keyword extracts <num of bytes> at a particular <offset> and stores it in <var_name>. The value in <var_name> can be used in any modifier that takes a number as an option and in the case of byte_test it can be used as a value.
Format:
byte_extract:<num of bytes>, <offset>, <var_name>, [,relative] [,multiplier <mult-value>] \
[,<endian>] [, dce] [, string [, <num_type>] [, align <align-value];
<num of bytes> |
The number of bytes selected from the packet to be extracted |
<offset> |
Number of bytes into the payload |
<var_name> |
The name of the variable in which to store the value |
[relative] |
Offset relative to last content match |
multiplier <value> |
multiply the extracted bytes by <mult-value> before storing |
[endian] |
Type of number being read: - big (Most significant byte at lowest address) - little (Most significant byte at the highest address) |
[string] <num> |
|
[dce] |
Allow the DCE module to determine the byte order |
align <align-value> |
Round the extracted value up to the next <align-value> byte boundary post-multiplication (if any) ; <align-value> may be 2 or 4 |
Keyword |
Modifier |
|---|---|
content |
offset,depth,distance,within |
byte_test |
offset,value |
byte_math |
rvalue |
byte_jump |
offset |
isdataat |
offset |
- alert tcp any any -> any any
(msg:"Byte_Extract Example Using distance"; content:"Alice"; byte_extract:2,0,size; content:"Bob"; distance:size; within:3; sid:1;)
- alert tcp any any -> any any
(msg:"Byte_Extract Example Using within"; flow:established,to_server; content:"|00 FF|"; byte_extract:1,0,len,relative; content:"|5c 00|"; distance:2; within:len; sid:2;)
- alert tcp any any -> any any
(msg:"Byte_Extract Example Comparing Bytes"; flow:established,to_server; content:"|00 FF|"; byte_extract:2,0,cmp_ver,relative; content:"FooBar"; distance:0; byte_test:2,=,cmp_ver,0; sid:3;)
8.9.18. entropy
The entropy keyword calculates the Shannon entropy value for content and compares it with
an entropy value. When there is a match, rule processing will continue. Entropy values
are between 0.0 and 8.0, inclusive. Internally, entropy is represented as a 64-bit
floating point value.
The entropy keyword syntax is the keyword entropy followed by options
and the entropy value and operator used to determine if the values agree.
The minimum entropy keyword specification is:
entropy: value <entropy-spec>
This results in the calculated entropy value being compared with entropy-spec using the (default) equality operator.
Example:
entropy: value 7.01
A match occurs when the calculated entropy and specified entropy values agree. This is determined by calculating the entropy value and comparing it with the value from the rule using the specified operator.
Example:
entropy: value <7.01
Options have default values: - bytes is equal to the current content length - offset is 0 - equality comparison
When entropy keyword options are specified, all options and "value" must be comma-separated. Options and value may be specified in any order.
The complete format for the entropy keyword is:
entropy: [bytes <byteval>] [offset <offsetval>] value <operator><entropy-value>
This example shows all possible options with default values and an entropy value of 4.037:
entropy: bytes 0, offset 0, value = 4.037
The following operators are available:
* = (default): Match when calculated value equals entropy value
* < Match when calculated value is strictly less than entropy value
* <= Match when calculated value is less than or equal to entropy value
* > Match when calculated value is strictly greater than entropy value
* >= Match when calculated value is greater than or equal to entropy value
* != Match when calculated value is not equal to entropy value
* x-y Match when calculated value is within the exclusive range
* !x-y Match when calculated value is not within the exclusive range
This example matches if the file.data content for an HTTP transaction has a Shannon entropy value of 4 or higher:
alert http any any -> any any (msg:"entropy simple test"; file.data; entropy: value >= 4; sid:1;)
8.9.18.1. Logging
When the entropy rule keyword is provided and the rule is evaluated, the
calculated entropy value is associated with the flow even if the calculated
entropy value didn't result in a match or alert. Subsequent logging of event
types that include the flow, including alerts, will contain the entropy value in
the metadata section of an output log. The follow is an example that shows
the calculated entropy value with the buffer on which the value was computed:
"metadata": {
"entropy": {
"file_data": 4.265743301617466
}
}
The events where entropy is logged will depend largely on how it's used within a rule and the rule's protocol.
For example -- this rule -- when evaluated by Suricata -- will result in the
calculated entropy being included in the alert, flow and http events.
Depending on the traffic and Suricata configuration, other event types may
include the entropy value:
alert http any any -> any any (flow:established; file.data; entropy: value > 4.4; sid: 1;)
8.9.19. rpc
The rpc keyword can be used to match in the SUNRPC CALL on the RPC procedure numbers and the RPC version.
You can modify the keyword by using a wild-card, defined with * With this wild-card you can match on all version and/or procedure numbers.
RPC (Remote Procedure Call) is an application that allows a computer program to execute a procedure on another computer (or address space). It is used for inter-process communication. See http://en.wikipedia.org/wiki/Inter-process_communication
Format:
rpc:<application number>, [<version number>|*], [<procedure number>|*]>;
Example of the rpc keyword in a rule:
alert udp $EXTERNAL_NET any -> $HOME_NET 111 (msg:"RPC portmap request yppasswdd"; rpc:100009,*,*; reference:bugtraq,2763; classtype:rpc-portmap-decode; sid:1296; rev:4;)
8.9.20. replace
The replace content modifier can only be used in IPS. It adjusts network traffic. It changes the content it follows ('abc') into another ('def'), see example:

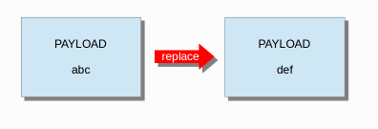
The replace modifier has to contain as many characters as the content it replaces. It can only be used with individual packets. It will not work for Normalized Buffers like HTTP uri or a content match in the reassembled stream.
The checksums will be recalculated by Suricata and changed after the replace keyword is being used.
Note
replace cannot be used in firewall mode,
even if only in Threat Detection rules.
8.9.21. pcre (Perl Compatible Regular Expressions)
The keyword pcre matches specific on regular expressions. More information about regular expressions can be found here http://en.wikipedia.org/wiki/Regular_expression.
The complexity of pcre comes with a high price though: it has a negative influence on performance. So, to mitigate Suricata from having to check pcre often, pcre is mostly combined with 'content'. In that case, the content has to match first, before pcre will be checked.
Format of pcre:
pcre:"/<regex>/opts";
Example of pcre. In this example there will be a match if the payload contains six numbers following:
pcre:"/[0-9]{6}/";
Example of pcre in a signature:
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{3,}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
There are a few qualities of pcre which can be modified:
By default pcre is case-sensitive.
The . (dot) is a part of regex. It matches on every byte except for newline characters.
By default the payload will be inspected as one line.
These qualities can be modified with the following characters:
i pcre is case insensitive
s pcre does check newline characters
m can make one line (of the payload) count as two lines
These options are perl compatible modifiers. To use these modifiers, you should add them to pcre, behind regex. Like this:
pcre: "/<regex>/i";
Pcre compatible modifiers
There are a few pcre compatible modifiers which can change the qualities of pcre as well. These are:
A: A pattern has to match at the beginning of a buffer. (In pcre ^ is similar to A.)E: Ignores newline characters at the end of the buffer/payload.G: Inverts the greediness.
Note
The following characters must be escaped inside the content:
; \ "
8.9.21.1. PCRE extraction
It is possible to capture groups from the regular expression and log them into the alert events.
There are 3 capabilities:
pkt: the extracted group is logged as pkt variable in
metadata.pktvarsalert: the extracted group is logged to the
alert.contextsubobjectflow: the extracted group is stored in a flow variable and end up in the
metadata.flowvars
To use the feature, parameters of pcre keyword need to be updated.
After the regular pcre regex and options, a comma-separated list of variable names.
The prefix here is flow:, pkt: or alert: and the names can contain special
characters now. The names map to the capturing substring expressions in order
pcre:"/([a-z]+)\/[a-z]+\/(.+)\/(.+)\/changelog$/GUR, \
flow:ua/ubuntu/repo,flow:ua/ubuntu/pkg/base, \
flow:ua/ubuntu/pkg/version";
This would result in the alert event having something like
"metadata": {
"flowvars": [
{"ua/ubuntu/repo": "fr"},
{"ua/ubuntu/pkg/base": "curl"},
{"ua/ubuntu/pkg/version": "2.2.1"}
]
}
The other events on the same flow such as the flow one will
also have the flow vars.
If this is not wanted, you can use the alert: construct to only
get the event in the alert
pcre:"/([a-z]+)\/[a-z]+\/(.+)\/(.+)\/changelog$/GUR, \
alert:ua/ubuntu/repo,alert:ua/ubuntu/pkg/base, \
alert:ua/ubuntu/pkg/version";
With that syntax, the result of the extraction will appear like
"alert": {
"context": {
"ua/ubuntu/repo": "fr",
"ua/ubuntu/pkg/base": "curl",
"ua/ubuntu/pkg/version": "2.2.1"
]
}
A combination of the extraction scopes can be combined.
It is also possible to extract key/value pair in the pkt scope.
One capture would be the key, the second the value. The notation is similar to the last
pcre:"^/([A-Z]+) (.*)\r\n/, pkt:key,pkt:value";
key and value are simply hardcoded names to trigger the key/value extraction.
As a consequence, they can't be used as name for the variables.
8.9.21.2. Suricata's modifiers
Suricata has its own specific pcre modifiers. These are:
R: Match relative to the last pattern match. It is similar to distance:0;U: Makes pcre match on the normalized uri. It matches on the uri_buffer just like uricontent and content combined with http_uri.U can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-uri buffer. Read more about HTTP URI Normalization.




I: Makes pcre match on the HTTP-raw-uri. It matches on the same buffer as http_raw_uri. I can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-raw-uri buffer. Read more about HTTP URI Normalization.P: Makes pcre match on the HTTP- request-body. So, it matches on the same buffer as http_client_body. P can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-request body.Q: Makes pcre match on the HTTP- response-body. So, it matches on the same buffer as http_server_body. Q can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-response body.H: Makes pcre match on the HTTP-header. H can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-header body.D: Makes pcre match on the unnormalized header. So, it matches on the same buffer as http_raw_header. D can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-raw-header.M: Makes pcre match on the request-method. So, it matches on the same buffer as http_method. M can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-method buffer.C: Makes pcre match on the HTTP-cookie. So, it matches on the same buffer as http_cookie. C can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-cookie buffer.S: Makes pcre match on the HTTP-stat-code. So, it matches on the same buffer as http_stat_code. S can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-stat-code buffer.Y: Makes pcre match on the HTTP-stat-msg. So, it matches on the same buffer as http_stat_msg. Y can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-stat-msg buffer.B: You can encounter B in signatures but this is just for compatibility. So, Suricata does not use B but supports it so it does not cause errors.O: Overrides the configures pcre match limit.V: Makes pcre match on the HTTP-User-Agent. So, it matches on the same buffer as http_user_agent. V can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-User-Agent buffer.W: Makes pcre match on the HTTP-Host. So, it matches on the same buffer as http_host. W can be combined with /R. Note that R is relative to the previous match so both matches have to be in the HTTP-Host buffer.
8.9.21.3. Changes from PCRE1 to PCRE2
The upgrade from PCRE1 to PCRE2 changes the behavior for some PCRE expressions.
\Iis a valid pcre in PCRE1, with a useless escape, so equivalent toI, but it is no longer the case in PCRE2. There are other characters than I exhibiting this pattern[\d-a]is a valid pcre in PCRE1, with either a digit, a dash or the charactera, but the dash must now be escaped with PCRE2 as[\d\-a]to get the same behaviorpcre2_substring_copy_bynumbernow returns an errorPCRE2_ERROR_UNSETinstead ofpcre_copy_substringreturning no error and giving an empty string. If the behavior of some use case is no longer the expected one, please let us know.